Xen on NUMA Machines
Contents
What is NUMA ?
Non-Uniform Memory Access (NUMA) means that memory accessing times of a program running on a CPU depends on the relative distance between that CPU and that memory. In fact, most of the NUMA systems are built in such a way that processors have their local memory, on which they can operate very fast. On the other hand, getting and storing data from and on remote memory (that is, memory local to some other processor) is quite more complex and slow. NUMA machines are becoming more and more common. Some examples of NUMA boxes/architectures are:
- dual (or more) 2376 Opteron solutions by AMD
- dual (or more) E5620 Xeon solutions by Intel
- the Intel SCC architecture
While on Linux (bare metal, so, no Xen), a pretty easy way to check whether your box is a NUMA one, and find out all its characteristics is the following:
# numactl --hardware available: 2 nodes (0-1) node 0 cpus: 0 1 2 3 8 9 10 11 node 0 size: 6055 MB node 0 free: 5968 MB node 1 cpus: 4 5 6 7 12 13 14 15 node 1 size: 5977 MB node 1 free: 5873 MB node distances: node 0 1 0: 10 20 1: 20 10
NUMA Performance Impact
NUMA awareness becomes very important as soon as many domains start running memory-intensive workloads on a shared host. In fact, the cost of accessing non node-local memory locations is very high, and the performance degradation is likely to be noticeable. For example, let's look at a memory-intensive benchmark with a bunch of competing VMs running concurrently on an host with 2 NUMA nodes.
The benchmark being run is SpecJBB2005. Host is a 16 pCPUs, 2-NUMA nodes Xeon, with 12GB RAM (2GB of which reserved for Dom0). Linux kernel for dom0 was 3.2, Xen was xen-unstable at the time of the benchmarking (i.e., more or less Xen 4.2). Guests have 4 vCPUs and 1GB of RAM each. Numbers come from running the benchmark on an increasing (1 to 8 ) number of Xen PV-guests at the same time, and repeating each run 5 times for each of the VMs configurations below:
- default is what was happening by default prior to Xen 4.2, i.e., no vCPU pinning at all;
- pinned means VM#1 was pinned on NODE#0 after being created. This implies its memory was striped on both the nodes, but it can only run on the fist one;
- all memory local is the best possible case, i.e., VM#1 was created on NODE#0 and kept there. That implies all its memory accesses are local;
- all memory remote is the worst possible case, i.e., VM#1 was created on NODE#0 and then moved (by explicitly pinning its pCPUs) on NODE#1. That implies all its memory accesses are remote.
In all the experiments, it is only VM#1 that was pinned/moved. All the other VMs have their memory "striped" between the two nodes and are free to run everywhere. The final score achieved by SpecJBB on VM#1 is reported below. As SpecJBB output is in terms of "business transactions per second (bops)", higher values correspond to better results.
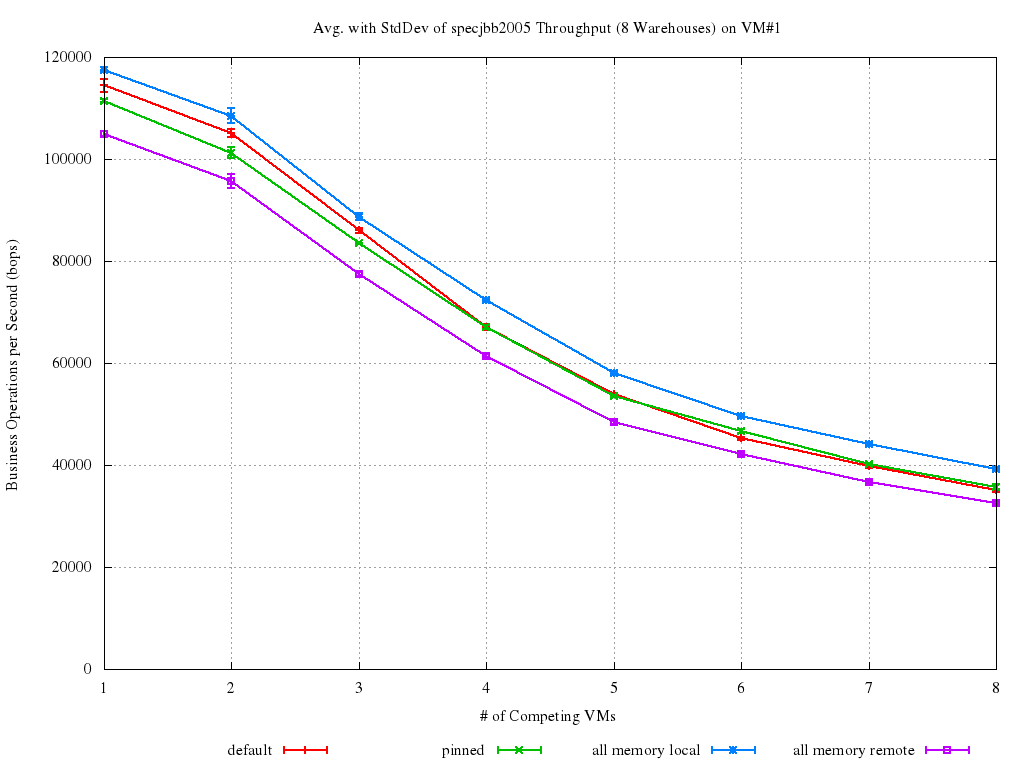
First of all, notice how small the standard deviation is for all the runs: this confirms SpecJBB is a good benchmark. The most interesting lines to look at and compare are the purple and the blue ones. In fact, that clearly shows how much getting NUMA right matters, even in such a small box!
The full set of results, with plots about all the statistical properties of the data set, can be found here.
NUMA and Xen
Xen is already capable of running on NUMA machines. First of all, while on Xen (well, on Dom0), figuring out the NUMA characteristics of the box goes by running xl info -n. Its output, on a 2 NUMA nodes machine, with 8 cores each (pCPUs 0-7 ==> Node #0, pCPUs 8-15 ==> Node #1) is as follows:
# xl info -n host : Zhaman release : 3.10.0 version : #1 SMP Mon Jul 8 23:16:42 UTC 2013 machine : x86_64 nr_cpus : 16 max_cpu_id : 63 nr_nodes : 2 cores_per_socket : 4 threads_per_core : 2 cpu_mhz : 2394 hw_caps : bfebfbff:2c100800:00000000:00003f00:029ee3ff:00000000:00000001:00000000 virt_caps : hvm hvm_directio total_memory : 12285 free_memory : 11604 ... cpu_topology : cpu: core socket node 0: 0 1 0 1: 0 1 0 2: 1 1 0 3: 1 1 0 4: 9 1 0 5: 9 1 0 6: 10 1 0 7: 10 1 0 8: 0 0 1 9: 0 0 1 10: 1 0 1 11: 1 0 1 12: 9 0 1 13: 9 0 1 14: 10 0 1 15: 10 0 1 numa_info : node: memsize memfree distances 0: 6144 5754 10,20 1: 6720 5850 20,10 ...
Xen deals with NUMA by assigning each domain a node affinity, which is the set of nodes of the host from which memory for that domain is allocated (in equal parts). This node affinity is liked to the subset of physical CPUs in the host the domain can or prefers to run. Acting like this, in fact, maximizes the probability of local memory accesses.
NUMA and vCPU pinning
At domain creation time, Xen constructs a domain's node affinity basing on what nodes the pCPUs to which the domain's vCPUs are pinned belong to. If no vCPU to pCPU pinning is specified at creation time (e.g., via the xl config file), what happens is described in the following section. To specify a vCPU pinning during domain creation, one should use the cpus="..." config option. For example, the excerpt below would create a 4 vCPU guest, with 1024 Mb of RAM, and all the 4 vCPUs will be pinned to pCPUs 0-3.
... vcpus = '4' memory = '1024' cpus = "0-3" ...
From a NUMA perspective, if pCPUs 0 to 3 belong all to the same NUMA node (say NUMA node 0), that means the node affinity of the domain will be set to node 0, and all its memory will be allocated on there.
NUMA and cpupools
Cpupools can also come handy in a NUMA system, especially if very large. In fact, they guarantee an even more strict partitioning and isolation than vCPU pinning. When a domain is created inside a cpupool, its node affinity is set to only the node(s) to which the pCPUs in the pool belong to. Have a look at how cpupool-numa-split works.
Automatic NUMA Placement
What happens at domain creation by default (i.e., if no cpus="..." or pool="..." option is present in config file), with respect to NUMA, varies (unfortunately) between the different Xen releases and toolstack used.
Starting from Xen 4.2, both XL and XenD toolstacks try to "guess" on which node(s) the domain could fit best. In fact, optimally fitting a set of VMs on the NUMA nodes of an host is an incarnation of the Bin Packing Problem, and therefore, an is what is used in both the toolstacks, XenD and XL (although not the same heuristics). The basic idea is as follows: among the node (or set of nodes) that have enough free memory and enough physical CPUs to accommodate the domain, the one with the smallest number of vCPUs already running there is chosen.
A more detailed description of automatic NUMA placement is available in the in tree documentation, or in this page. Some "history", and the roadmap for future improvement to automatic NUMA placement is available here.
Automatic NUMA Placement and Migration
From the migration target host perspective, migration is just a kind of special form of domain creation. Therefore, unless the config file (received from the source target) says otherwise, automatic NUMA placement just takes place normally, exactly as it happens with new domains. That means there is no guarantee for the final decision from the placing algorithm on the target machine to be "compatible" with the one made on the source machine at initial domain creation time. For instance, if the domain fits in just one node and is placed there on the source host, it can well end up being split on two or more nodes when migrated on the target host (and the vice-versa).
Currently this is considered acceptable, especially as there is not way to expose any virtual NUMA topology to the VM itself. As soon as some support for that will be introduced, this behavior might change accordingly.
Automatic NUMA Placement and Virtual Topology
Currently (i.e., up to Xen 4.4) there is no way for a domain --either dom0 or domU-- to have a virtual NUMA topology. As soon as this capability will be introduced (and it is indeed under development), that may affect the automatic placement. See the status and the roadmap here.
NUMA Aware Scheduling
NUMA aware scheduling, as it has been included in Xen 4.3, means that it is possible for vCPUs of a domain to just prefer to run on the pCPUs of some NUMA node. The vCPUs will still be allowed, though, to run on every pCPU, guaranteed much more flexibility than having to use pinning.
More details about the solution adopted for NUMA aware scheduling in Xen 4.3 is available in this page.
Querying Memory Distribution
Up to Xen 4.4, there is no easy way to figure out how much memory from each domain has been allocated on each NUMA node in the host. A workaround to that, is exploiting one of the Xen debug keys, by issueing the following commands:
# xl debug-keys u # xl dmesg | tail -n40
A possible output is as follows:
(XEN) 'u' pressed -> dumping numa info (now-0x3F5:9821EF14) (XEN) idx0 -> NODE0 start->1720320 size->1572864 free->1473152 (XEN) phys_to_nid(00000001a4001000) -> 0 should be 0 (XEN) idx1 -> NODE1 start->0 size->1720320 free->1235505 (XEN) phys_to_nid(0000000000001000) -> 1 should be 1 (XEN) CPU0 -> NODE0 (XEN) CPU1 -> NODE0 (XEN) CPU2 -> NODE0 (XEN) CPU3 -> NODE0 (XEN) CPU4 -> NODE0 (XEN) CPU5 -> NODE0 (XEN) CPU6 -> NODE0 (XEN) CPU7 -> NODE0 (XEN) CPU8 -> NODE1 (XEN) CPU9 -> NODE1 (XEN) CPU10 -> NODE1 (XEN) CPU11 -> NODE1 (XEN) CPU12 -> NODE1 (XEN) CPU13 -> NODE1 (XEN) CPU14 -> NODE1 (XEN) CPU15 -> NODE1 (XEN) Memory location of each domain: (XEN) Domain 0 (total: 130998): (XEN) Node 0: 62804 (XEN) Node 1: 68194 (XEN) Domain 1 (total: 262144): (XEN) Node 0: 0 (XEN) Node 1: 262144
In this case, Domain 0 has 62804 pages allocated on NUMA node 0, and 68194 on node 1. On the other hand, Domain 1 has all its 262144 pages allocated out of node 1. A more straightforward mechanism for querying on what node(s) domains' memory is allocated is under development, and will (probably) be available in Xen 4.5.
NUMA in Other Virtualization Platforms
Some information on how NUMA is handled in VMWare virtualization solutions can be found here:
- "Using NUMA Systems with ESX/ESXi"
- "Performance Evaluation of HPC Benchmarks on VMware’s ESXi Server".
And some on NUMA in Linux here:
Performance Evaluation and Benckmarks
When NUMA is involved, it is always wise to do some experimental evaluation, in order to figure out whether a particular feature we just finished implementing is actually improving performance (or, OTOH, is not causing perf. regressions). Benchmarks should be run inside a varying number of VMs running concurrently.
Up to now, useful numbers have been obtained from the following bench. suites:
- SpecJBB2005: really looks a good one, very stable and consistent resutls.
- lmbench (some of the lat_*): seems good, but needs more investigation.
- stream: should be considered, but seems to have issues running with more than one thread (needs more investigation).
Future Developments
Preliminary patches introducing support for automatic placement in xl and NUMA-aware scheduling were posted to the xen-devel mailing list a while back. The results of some (preliminary as well) benchmarks have been discussed in this and this Blog posts (as well as in this Wiki article).
Xen 4.2 contains a slightly modified version of that placement algorithm (described above), more specifically, the one implemented by this patch series. Xen 4.3 improved on this, by adding NUMA aware scheduling. Development of all the various missing features is, of course, still ongoing, and we plan to add a bunch of new features wrt to NUMA, in Xen 4.5.
Keeping improving it, as well as continuing adding NUMA related features will happen throughout the Xen 4.3 development cycle (so keep yourself posted!).
This Wiki also hosts a sort of Xen NUMA Roadmap or, better, the list of items that will be getting some Xen developers' attentions in the upcoming months... Feel free to contribute if thinking something could be missing or wrong.