Xen 4.3 NUMA Aware Scheduling
When dealing with NUMA machines, it is (among other things) very important that we:
- achieve a good initial placement, when creating a new VM;
- have a solution that is both flexible and effective enough to take advantage of that placement during the whole VM lifetime.
The latter, which basically, means: <<When starting a new Virtual Machine, to which NUMA node should I "associate" it with?>>. The latter is more about: <<How hard should the VM be associated to that NUMA node? Could it, perhaps temporarily, run elsewhere?>>, is what is usually called NUMA aware scheduling.
This document aims at describing what was included, regarding NUMA aware scheduling, in Xen 4.3. You can find other articles about NUMA in the NUMA category.
Preliminary/Exploratory Work
Suppose we have a VM with all its memory allocated on NODE#0 and NODE#2 of our NUMA host. One may think that the best thing to do would be to pin the VM’s vCPUs on the pCPUs related to the two nodes. However, pinning is quite unflexible: what if those pCPUs get very busy while there are completely idle pCPUs on other nodes? It will depend on the workload, but it is not hard to imagine that having some chance to run --even if on a remote node-- would be better than not running at all.
The idea is, then, to give the scheduler some hints about where a VM’s vCPUs should be executed (and this preference, in this context, will be called from now on NUMA affinity). It then can try at its best to honor these suggestions of ours, but not at the cost of subverting its own algorithm. Here they are some early experimental results for this idea (dating back to [http://lists.xen.org/archives/html/xen-devel/2012-04/msg00732.html this patchset). The various curves in the graph below represents the throughput achieved one VM when it is:
- scheduled without any pinning or NUMA affinity, i.e., cpus="all" in the config file (the red line);
- pinned on NODE#0, so that all its memory accesses are local (the green line);
- scheduled with NUMA affinity set to NODE#0, and no pinning, (blue line).
The plot shows is the percent increase of each configuration with respect to the worst possible case (i.e., when all memory access are remote).
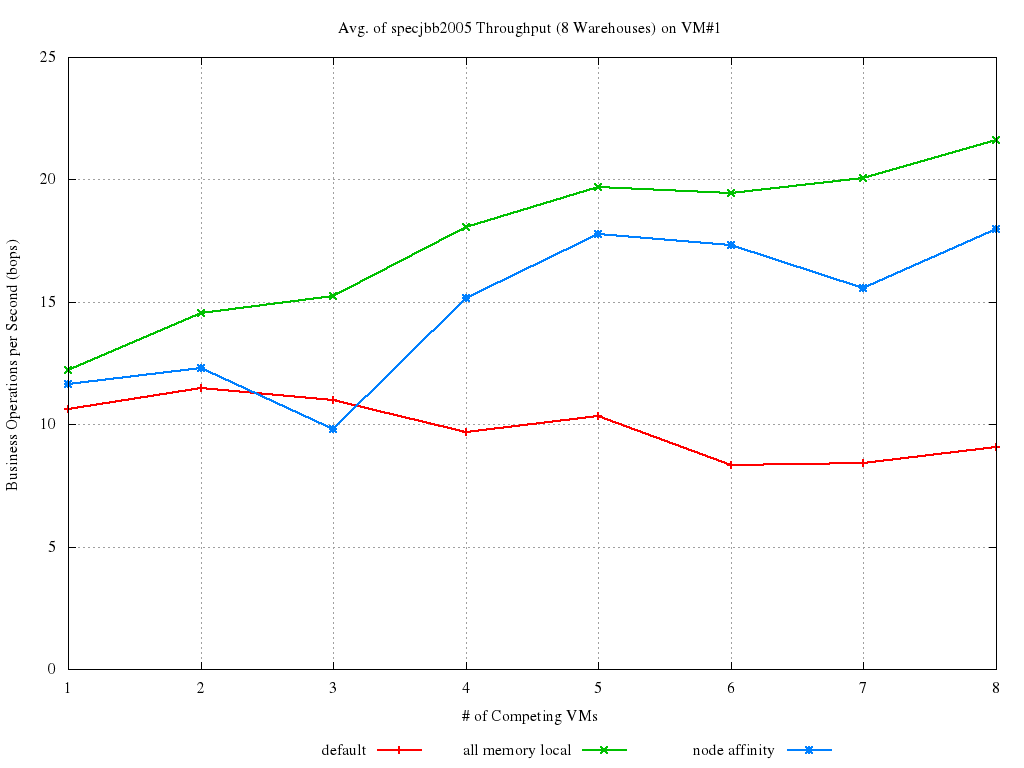
It appears quite clear that, introducing NUMA affinity increases performance by ~12% to ~18% from the worst case. It enables up to ~8% performance increase, as compared to unpinned behavior, and that the higher the load on the host, the better.
The full set of results for these early benchmarks is available here. There was a blog post about this, and it is still online at this address.
The Actual Solution in Xen 4.3
Automatic placement made it to Xen 4.2, and that meant, when a VM is created, a (set of) NUMA node(s) is picked to store its memory, and its vCPUs statically pinned to the pCPUs of such node(s). With NUMA aware scheduling, which was included in Xen 4.3, the latter is no longer the case. In fact, instead of using pinning, the vCPUs strongly prefers to run on the pCPUs of the NUMA node(s), but they can run somewhere else as well.
During development, more benchmarks were run. For example the following ones:
- SpecJBB: this is all about throughput, thus pinning is likely the ideal solution;
- Sysbench-memory: this is the time it takes for writing a fixed amount of memory (and then it is the throughput that is measured). What we expect is locality to be important, but at the same time the potential imbalances due to pinning could have a say in it;
- LMBench-proc: this is the time it takes for a process to fork a fixed number of children. This is much more about latency than throughput, with locality of memory accesses playing a smaller role and, again, imbalances due to pinning being a potential issue.
The host was a 2 NUMA box, where 2 to 10 VMs (2 vCPUs and 960 RAM each) were executing the various benchmarks concurrently. The results looks as follows:
---------------------------------------------------- | SpecJBB2005, throughput (the higher the better) | ---------------------------------------------------- | #VMs | No affinity | Pinning | NUMA scheduling | | 2 | 43318.613 | 49715.158 | 49822.545 | | 6 | 29587.838 | 33560.944 | 33739.412 | | 10 | 19223.962 | 21860.794 | 20089.602 | ---------------------------------------------------- | Sysbench memory, throughput (the higher the better) ---------------------------------------------------- | #VMs | No affinity | Pinning | NUMA scheduling | | 2 | 469.37667 | 534.03167 | 555.09500 | | 6 | 411.45056 | 437.02333 | 463.53389 | | 10 | 292.79400 | 309.63800 | 305.55167 | ---------------------------------------------------- | LMBench proc, latency (the lower the better) | ---------------------------------------------------- | #VMs | No affinity | Pinning | NUMA scheduling | ---------------------------------------------------- | 2 | 788.06613 | 753.78508 | 750.07010 | | 6 | 986.44955 | 1076.7447 | 900.21504 | | 10 | 1211.2434 | 1371.6014 | 1285.5947 | ----------------------------------------------------
Which, reasoning in terms of %-performance increase/decrease, means NUMA aware scheduling does as follows, as compared to no-affinity at all and to static pinning:
---------------------------------- | SpecJBB2005 (throughput) | ---------------------------------- | #VMs | No affinity | Pinning | | 2 | +13.05% | +0.21% | | 6 | +12.30% | +0.53% | | 10 | +4.31% | -8.82% | ---------------------------------- | Sysbench memory (throughput) | ---------------------------------- | #VMs | No affinity | Pinning | | 2 | +15.44% | +3.79% | | 6 | +11.24% | +5.72% | | 10 | +4.18% | -1.34% | ---------------------------------- | LMBench proc (latency) | | NOTICE: -x.xx% = GOOD here | ---------------------------------- | #VMs | No affinity | Pinning | ---------------------------------- | 2 | -5.66% | -0.50% | | 6 | -9.58% | -19.61% | | 10 | +5.78% | -6.69% | ----------------------------------
The tables show how, when not in overload (where overload='more vCPUs than pCPUs'), NUMA aware scheduling is the absolute best. In fact, not only it does a lot better than no-pinning on throughput biased benchmarks, and a lot better than pinning on latency biased benchmarks (especially with 6 VMs), it also equals or beats both under adverse circumstances (adverse to NUMA aware scheduling, i.e., beats/equals pinning in throughput benchmarks, and beats/equals no-affinity on the latency benchmark).
When the system is overloaded, NUMA scheduling scores in the middle, as it could have been expected. It must also be noticed that, when it brings benefits, they are not as huge as in the non-overloaded case (which probably means there is still room for some more optimization). In particular, the current way a pCPU is selected, when a vCPU waks-up, couples particularly bad with the new concept of NUMA affinity. Changing this is not trivial, because it involves rearranging some locks inside, but can be done, if deemed worthwhile.
The in tree documentation has some more details about NUMA aware scheduling, and the interactions it has with automatic NUMA placement. Also, there was a blog post about this topic too, available here.
Soft Scheduling Affinity
Starting from Xen 4.5, credit1 supports two forms of affinity: hard and soft, both on a per-vCPU basis. This means each vCPU can have its own soft affinity, stating where such vCPU prefers to execute on. This is less strict than what it (also starting from 4.5) is called hard affinity, as the vCPU can potentially run everywhere, it just prefers some pCPUs rather than others. In Xen 4.5, therefore, NUMA-aware scheduling is achieved by matching the soft affinity of the vCPUs of a domain with its node-affinity.
In fact, as it was for 4.3, if all the pCPUs in a vCPU's soft affinity are busy, it is possible for the domain to run outside from there. The idea is that slower execution (due to remote memory accesses) is still better than no execution at all (as it would happen with pinning). For this reason, NUMA aware scheduling has the potential of bringing substantial performances benefits, although this will depend on the workload.
Therefore, for each vCPU, the following three scenarios are possbile:
- a vCPU is pinned to some pCPUs and does not have any soft affinity. In this case, the vCPU is always scheduled on one of the pCPUs to which it is pinned, without any specific peference among them.
- a vCPU has its own soft affinity and is not pinned to any particular pCPU. In this case, the vCPU can run on every pCPU. Nevertheless, the scheduler will try to have it running on one of the pCPUs in its soft affinity;
- a vCPU has its own vCPU soft affinity and is also pinned to some pCPUs. In this case, the vCPU is always scheduled on one of the pCPUs onto which it is pinned, with, among them, a preference for the ones that also forms its soft affinity. In case pinning and soft affinity form two disjoint sets of pCPUs, pinning "wins", and the soft affinity is just ignored.
Finally, soft affinity is not necessarily related to the NUMA characteristics of the host, and can be tweaked independently for achieve arbitrary results. See here for more details about it.