Xen 4.2 Automatic NUMA Placement
With NUMA placement, we refer to the decision on out of which NUMA nodes in an host the memory for a newly created VM should be allocated. Unfortunately, fitting VMs on a NUMA host is an incarnation of the Bin Packing Problem, which means it is NP-hard, so heuristics is the only reasonable way to go.
This document provides information about exploratory work on NUMA placement, as well as a description of what was included in Xen 4.2. You can find other articles about NUMA in the NUMA category.
Preliminary/Exploratory Work
The first attempt of moving NUMA placement away of XEND's python code (to, in that case, libxc) dates back to 2010 (can't find the link anymore).
More recently, this patch series was released as an RFC on April 2012. In patches 8/10 and 9/10, it implemented three possible placement policies:
- greedy, which scans the host’s node and put the new VM on the first one that is found to have enough free memory;
- packed, which puts the new VM on the node that has the smallest amount of free memory (although still enough for the VM to fit there);
- spread, which puts the new VM on the node that has the biggest amount of free memory.
The names comes from the intrinsic characteristics of the three algorithms. In fact, greedy just grabs the first suitable node, packed tends to keep nodes as full as possible while spread tries to keep them as free/empty as possible. Notice that keeping the nodes full or empty should be intended memory-wise here, but that it also imply the following:
- greedy and packed policies are both incline to put as much VMs as possible on one node before moving on to try others (which one does that most, depends on the VMs' characteristics and creation order);
- spread is incline to distribute the VMs across the various nodes (although again, it will depend somehow on VMs' characteristics).
"Scientifically" speaking, greedy is based on the First Fit algorithm, packed is based on Best Fit and spread on Worst Fit.
Some benchmarks, of all the three policies, were performed (as explained in details here). One of the obtained graphs is reported below. This shows the aggregate result of the SpecJBB2005 benchmark, concurrently run inside multiple VMs
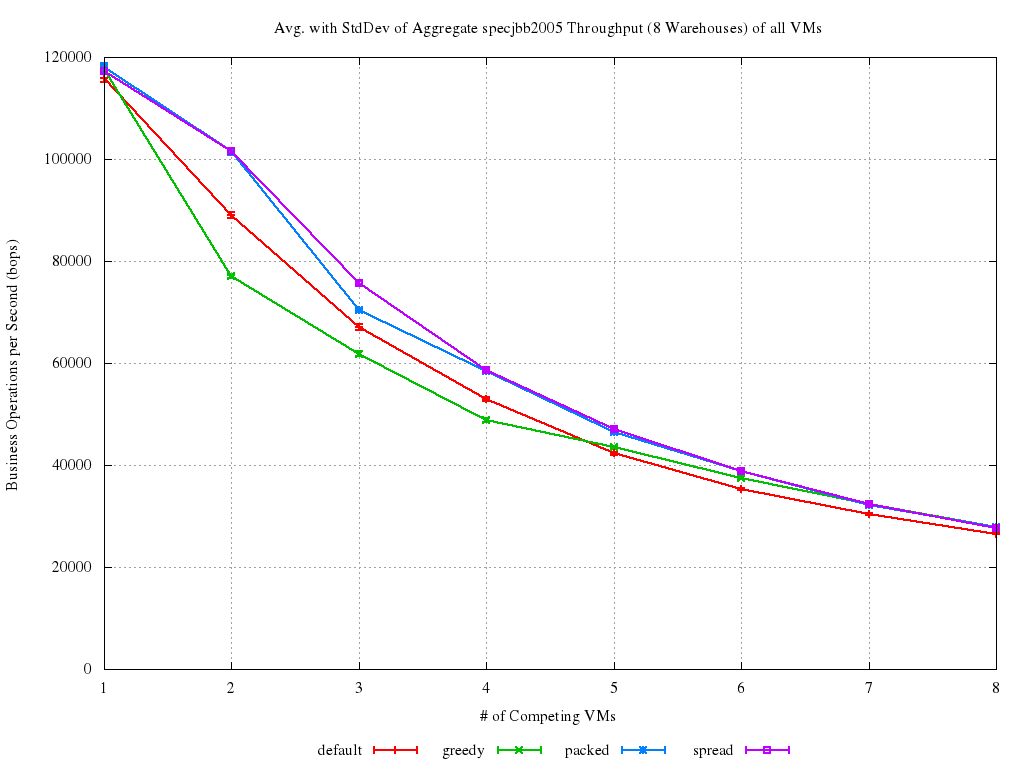
That served as a quite effective confirmation that the spread (i.e., the one based on the worst fit algorithm) policy was the absolute best, and thus, in the continuation of the work on automatic placement, the othe twos could be neglected.
There was also a blog post about this, and it is still available here.
The Actual Solution in Xen 4.2
Keeping on experimenting and benchmarking (full history available here), it was proved that proper VM placement can improve performances significantly. As in here, the curves, in the graph below, have the following meaning:
- default is what was happening by default prior to Xen 4.2, i.e., no vCPU pinning at all;
- pinned means VM#1 was pinned on NODE#0 after being created. This implies its memory was striped on both the nodes, but it can only run on the fist one;
- all memory local is the best possible case, i.e., VM#1 was created on NODE#0 and kept there. That implies all its memory accesses are local;
What is shown is the in performance, for increasing (1 o 8) number of VMs, with respect to the worst possible case case (all memory remote).
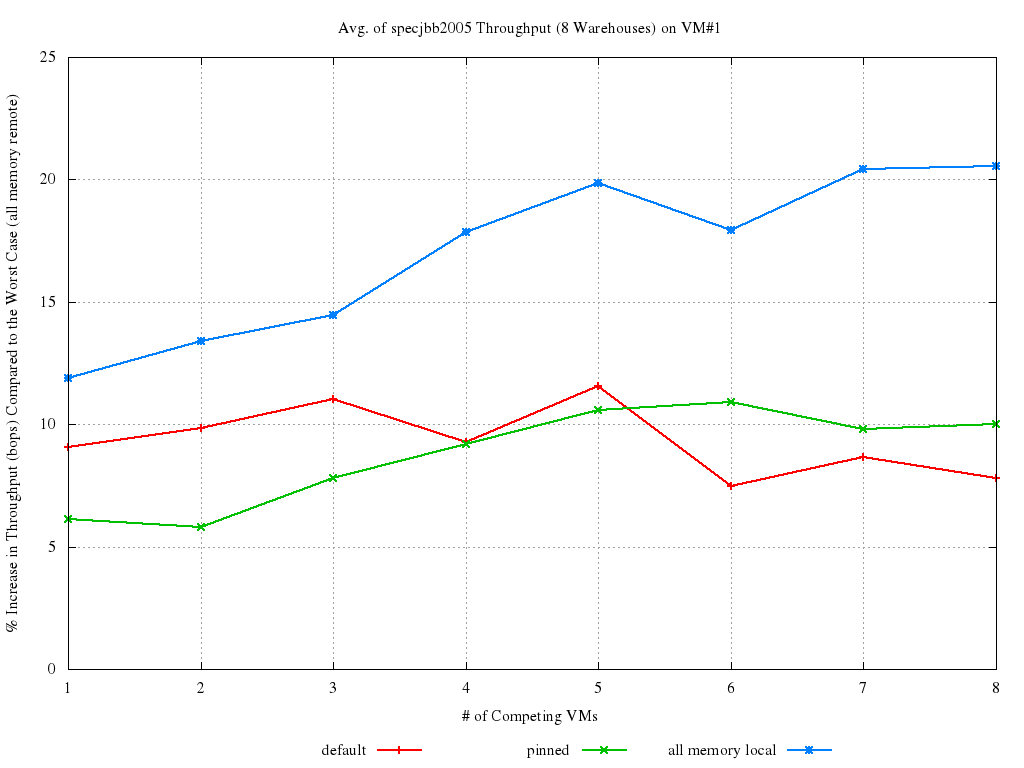
This makes evident that NUMA placement is accountable for a ~10% to 20% (depending on the load) impact. Also, it appears that just pinning the vCPUs to some pCPUs, although it can help in keeping the performance consistent, is not able to get that close to the best possible situation.
That led to the implementation of a proper solution for NUMA placement, which became the default XL behavior (as described Xen_on_NUMA_Machines#Automatic_NUMA_Placement here]]), starting from Xen 4.2. In some more details (with reference to the libxl implementation):
- of all the nodes (or sets of nodes) that have enough free memory and enough pCPUs (at least as much as the domain's vCPUs) are found, and considered placement candidates
- if there is more than one candidate:
- in case more than one node is necessary, solutions involving fewer nodes are considered better. In case two (or more) candidates span the same number of nodes,
- the candidate with a fewer of vCPUs runnable on it (due to previous placement and/or plain vCPU pinning) is considered better. In case the same number of vCPUs can run on two (or more) candidates,
- the candidate with with the greatest amount of free memory is considered to be the best one.
To actually place the domain on a candidate (node or set of nodes), this is what happens:
- in Xen 4.2, all the domain's vCPUs are statically pinned to the pCPUs of the node(s);
- starting from Xen 4.3, which supports NUMA aware scheduling (at least for the credit scheduler), and only with XL, there is no pinning involved, it is only the node affinity that is set to the node(s) in question. That means the vCPUs are free to run everywhere, but they'll prefer the pCPUs of the selected node(s).
Due to the fact that libxl and XL where just technical preview at the time, in Xen 4.1, the default behavior, for XL, is just "nothing happens". So, if not cpus="..." or pool="..." are specified in the config file, neither pinning nor node affinity will be affected, and the domain will be able to run on every pCPU, and will have its memory spread on all nodes. Conversely, if XenD is used, the behavior is the same as the one described above for Xen 4.2.
In all versions and for both toolstacks, if any vCPU pinning and/or cpupool assignment is manually setup (see at the Tuning page), no automatic placement happens at all, and the user's requests are honored.
The in the in tree documentation has all the details, and is guaranteed to be updated. Some "history", and the roadmap for future improvement to automatic NUMA placement is available here.