Difference between revisions of "Xen 4.2 Automatic NUMA Placement"
Lars.kurth (talk | contribs) m |
(Restructured the document to contain all the benchamrking results obtained so far) |
||
| Line 1: | Line 1: | ||
| + | = Benchmarking NUMA = |
||
| − | == NUMA Scheduling, what is it == |
||
| + | Providing a domain with some form of "NUMA Affinity" (see [[Xen_NUMA_Introduction|here]] is very important, especially for performances. That's why both XenD and libxl/xl (starting from Xen 4.2) based toolstacks tries to figure out on their own on what nodes (and as a consequence on what physical CPUs) to put a new domain and pin it there |
||
| − | Suppose we have a VM with all its memory allocated on NODE#0 and NODE#2 of our NUMA host. As already said, the best thing to do would be to pin the VM’s vCPUs on the pCPUs related to the two nodes. However, pinning is quite unflexible: what if those pCPUs get very busy while there are completely idle pCPUs on other nodes? It will depend on the workload, but it is not hard to imagine that having some chance to run –even if on a remote node– would be better than not running at all! It is therefore preferable to give the scheduler some hints about where a VM’s vCPUs should be executed. It then can try at its best to honor these requests of ours, but not at the cost of subverting its own algorithm. From now on, we’ll call this hinting mechanism node affinity (don’t confuse it with CPU affinity, which is about to static CPU pinning). |
||
| + | Dealing with NUMA ny means of [[Xen_4.2:_cpupools|cpupools]] (e.g., '''xl cpupool-numa-split''') is of course possible, but it needs to be setup by hand, while something automatic could be desirable. |
||
| − | The experimental [http://lists.xen.org/archives/html/xen-devel/2012-04/msg00732.html patchset] introduced in [[Xen_NUMA_Introduction|Part I]] of this series introduces the support for node affinity aware scheduling with this one changeset here: [sched_credit: Let the [http://lists.xen.org/archives/html/xen-devel/2012-04/msg00739.html scheduler know about `node affinity`]. As of now, it is all very simple, and it only happens for the credit1 scheduling plugin of the Xen hypervisor. However, looking at some early performance measurements seems promising (see below). |
||
| + | The [http://www.spec.org/jbb2005/ SpecJBB2005] benchmarks has been run concurrently within 1 to 8 (4 VCPUs/1GB RAM) VMs, running on a two NUMA nodes, 16 cores, system with 12 GB of RAM. |
||
| − | Oh, on a related note, and as a confirmation that this NUMA scheduling thing is an hot topic for the whole Open Source OS and Virtualization community, here it is [http://lwn.net/Articles/486858/ what’s happening in the Linux kernel about it!] |
||
| − | == |
+ | == NUMA Placement == |
| − | First of all, optimally fitting VMs on a NUMA host is an incarnation of the [http://en.wikipedia.org/wiki/Bin_packing_problem Bin Packing Problem], which means it is [http://en.wikipedia.org/wiki/NP-hard NP-hard] |
+ | First of all, just notice that optimally fitting VMs on a NUMA host is an incarnation of the [http://en.wikipedia.org/wiki/Bin_packing_problem Bin Packing Problem], which means it is [http://en.wikipedia.org/wiki/NP-hard NP-hard], so an heuristic approach must be undertaken. |
| − | Bin Packing |
||
| + | Concentrating on memory, what if we have a bunch of nodes, each with its own amount of free memory, and we need to decide where a new VM should be placed? [http://lists.xen.org/archives/html/xen-devel/2012-04/msg00732.html This] RFC patch series includes two patches ([http://lists.xen.org/archives/html/xen-devel/2012-04/msg00741.html 8/10] and [http://lists.xen.org/archives/html/xen-devel/2012-04/msg00740.html 9/10]) implementing three possible NUMA placement policies: |
||
| − | Let’s concentrate just on memory, for now. What if you have a bunch of nodes, each with its own amount of free memory, and you need to decide where a new VM should be placed? (Ok, fine, you may assume the size of the VM is in terms of memory to be known.) We, for example, can look for all the nodes that have enough free memory to host the whole RAM of our VM, but then, which one should we chose? The first we find? The one with most free memory? The one with least free memory? A random one? Moreover, what if we can’t find any of them with enough free space for the domain… Should we try with a set of nodes? If yes, how big? And of which nodes? Well, if you’re guessing that one can go on putting this kind of question all together, then you’re right. After all, that’s basically what NP-hard means! |
||
| − | Point is some choices have to be made, and exploiting a couple of heuristics to get out of the marsh sounds like The Right Thing (TM). The very same RFC series mentioned above includes two patches which are trying to put that in place, [http://lists.xen.org/archives/html/xen-devel/2012-04/msg00741.html patch 8 out of 10] and [http://lists.xen.org/archives/html/xen-devel/2012-04/msg00740.html patch 9 out of 10]. They introduce three possible NUMA placement policies: |
||
| − | * greedy, which scans the host’s node and put the VM on the first one that is found to have enough free memory; |
+ | * ''greedy'', which scans the host’s node and put the VM on the first one that is found to have enough free memory; |
| − | * packed, which puts the VM on the node that has the smallest amount of free memory (although still enough for the VM to fit there); |
+ | * ''packed'', which puts the VM on the node that has the smallest amount of free memory (although still enough for the VM to fit there); |
| − | * spread, which puts the VM on the node that has the biggest amount of free memory. |
+ | * ''spread'', which puts the VM on the node that has the biggest amount of free memory. |
The names comes from the intrinsic characteristics of the three algorithms. In fact, greedy just grabs the first suitable node, packed tends to keep nodes as full as possible while spread tries to keep them as free/empty as possible. Notice that keeping the nodes full or empty should be intended memory-wise here, but that it also imply the following: |
The names comes from the intrinsic characteristics of the three algorithms. In fact, greedy just grabs the first suitable node, packed tends to keep nodes as full as possible while spread tries to keep them as free/empty as possible. Notice that keeping the nodes full or empty should be intended memory-wise here, but that it also imply the following: |
||
| − | * greedy and packed policies are both incline to put as much VMs as possible on one node before moving on to try others (which one does that most, depends on the |
+ | * greedy and packed policies are both incline to put as much VMs as possible on one node before moving on to try others (which one does that most, depends on the VMs' characteristics and creation order); |
| − | * spread is incline to distribute the VMs across the various nodes (although again, it will depend somehow on |
+ | * spread is incline to distribute the VMs across the various nodes (although again, it will depend somehow on VMs' characteristics). |
| − | + | "Scientifically" speaking, greedy is based on the [http://www.youtube.com/watch?v=4QBdzVD3AbE First Fit ] algorithm, packed is based on [http://www.youtube.com/watch?v=QSXB693Hrls Best Fit] and spread on [http://www.youtube.com/watch?v=OwUIiSf0c-U Worst Fit]. |
|
| + | For benchmarking the placement heuristics (full results available [http://xenbits.xen.org/people/dariof/benchmarks/specjbb2005-numa_aggr/ here]), on the other hand, all the VMs have been created asking xl to use either the greedy, packed or spread policy. The aggregate throughput is then computed by summing the throughput achieved in all the VMs (and averaging the result). |
||
| − | The problem of VMs too big for just one node is addressed too, but going into too much technical details is out of the scope of this post. |
||
| + | http://xenbits.xen.org/people/dariof/images/blog/NUMA_2/kernbench_avgstd2.png |
||
| − | == Numbers! Numbers! Numbers! == |
||
| + | It is easy to see that (in this case) both spread and packed placement works better than unpinned. That should have been expected, especially for spread, as it manages in distributing the load a bit better. Given the specific characteristics of this experiment, it should also have also been expected for greedy to behave very bad when load is small. In fact, with less than 5 VMs, all of them fit on the first NUMA node. This means memory accesses are local, but the load distribution is clearly sub-optimal. Also, the benefit we get from NUMA affinity seems to get smaller with the increase of the VM count. This probably have some relationship with the CPU overcommitment (starting at 5 VM). |
||
| − | As it was for the previous post on this, here’s what my NUMA test box has churned out after some days of running SpecJBB2005. The setup is exactly equal to the one described in [[[[Xen_NUMA_Introduction|Part I]]. That is, basically, 1 to 8 count of 4 VCPUs / 1GB RAM VMs running SpecJBB2005 concurrently on a 16 ways / 12GB RAM shared host (drop an eye at the “Some numbers or, even better, some graphs!” section there for more details). |
||
| − | As far as scheduling is concerned, our attempt to suggest the scheduler the preferred node for a VM is at least going in the right direction (For the interested, complete results set is [http://xenbits.xen.org/people/dariof/benchmarks/specjbb2005-numa/ here]). The various curves in the graph below represents the throughput achieved on one of the VMs, more specifically the one that is being, respectively: |
||
| + | == NUMA Scheduling == |
||
| − | * scheduled without any pinning or affinity, i.e., default Xen/xl behaviour (red line), |
||
| + | |||
| + | Suppose we have a VM with all its memory allocated on NODE#0 and NODE#2 of our NUMA host. Of course, the best thing to do would be to pin the VM’s vCPUs on the pCPUs related to the two nodes. However, pinning is quite unflexible: what if those pCPUs get very busy while there are completely idle pCPUs on other nodes? It will depend on the workload, but it is not hard to imagine that having some chance to run –even if on a remote node– would be better than not running at all. It would therefore be preferable to give the scheduler some hints about where a VM’s vCPUs should be executed. It then can try at its best to honor these requests of ours, but not at the cost of subverting its own algorithm. From now on, we’ll call this hinting mechanism node affinity (don’t confuse it with CPU affinity, which is about to static CPU pinning). |
||
| + | |||
| + | As said, the experimental [http://lists.xen.org/archives/html/xen-devel/2012-04/msg00732.html patchset] introduces also the support for node affinity aware scheduling by means of this changeset: [sched_credit: Let the [http://lists.xen.org/archives/html/xen-devel/2012-04/msg00739.html scheduler know about `node affinity`]. As of now, it is all very simple, and it only happens for the '''credit1''' scheduling plugin of the Xen hypervisor. However, looking at some early performance measurements seems promising. |
||
| + | |||
| + | Looking at the results, attempts to suggest the scheduler the preferred node for a VM seem to be the righ direction to go (For the interested, complete results set is [http://xenbits.xen.org/people/dariof/benchmarks/specjbb2005-numa/ here]). The various curves in the graph below represents the throughput achieved on one of the VMs, more specifically the one that is being, respectively: |
||
| + | |||
| + | * scheduled without any pinning or affinity, i.e., (''cpus="all"'' in the VM config file, red line, also called default in this article), |
||
* created and pinned on NODE#0, so that all its memory accesses are local (green line), |
* created and pinned on NODE#0, so that all its memory accesses are local (green line), |
||
* scheduled with node affinity only to NODE#0 (no pinning) as per what is introduced by the patch (blue line). |
* scheduled with node affinity only to NODE#0 (no pinning) as per what is introduced by the patch (blue line). |
||
| Line 40: | Line 45: | ||
http://xenbits.xen.org/people/dariof/images/blog/NUMA_2/kernbench_avg2.png |
http://xenbits.xen.org/people/dariof/images/blog/NUMA_2/kernbench_avg2.png |
||
| − | What the plot actually shows is the percent increase of each configuration with respect to the worst possible case (i.e., when all memory access are remote). This means |
+ | What the plot actually shows is the percent increase of each configuration with respect to the worst possible case (i.e., when all memory access are remote). This means tweaking node affinity increases performance by ~12% to ~18% from the worst case. Also, it lets us gain up to ~8% performance as compared to unpinned behavior, doing particularly well as load increases. However, although it gets quite close to the green line (which is the best case), there is still probably some performance bits to squeeze from it. |
| + | == Combining Placement and Scheduling == |
||
| − | For benchmarking the placement heuristics (full results available [http://xenbits.xen.org/people/dariof/benchmarks/specjbb2005-numa_aggr/ here]), on the other hand, all the VMs have been created asking Xen (well, xl) to use either the greedy, packed or spread policy. The aggregate throughput is then computed by summing the throughput achieved in all the VMs (and averaging the result). |
||
| + | So, if we do both things, i.e.: |
||
| − | http://xenbits.xen.org/people/dariof/images/blog/NUMA_2/kernbench_avgstd2.png |
||
| + | * Introduce some form of automatic domain placement logic in the new Xen toolstack (basically, in xl). This means assigning a "node affinity" to a domain at creation time and asking Xen to stick to it. |
||
| − | It is easy to see that (in this case) both spread and packed placement works better than the default xl behaviour. That should have been expected, especially for spread, as it manages in distributing the load a bit better. Given the specific characteristics of this experiment, it should also have also been expected for greedy to behave very bad when load is small. In fact, with less than 5 VMs, all of them fit on the first NUMA node. This means memory accesses are local, but the load distribution is clearly sub-optimal. Also, the benefit we get from NUMA affinity seems to get smaller with the increase of the VM count. We suspect this to have some relationship with the CPU overcommitment (starting at 5 VM). We will perform more benchmarks to confirm or contradict that as, again, this is all a work in progress. |
||
| + | * Tweak the scheduler to so that it will strongly prefer to run a domain on the node(s) it has affinity with, but not in a strict manner as it is for pinning. For instance, it would be nice to avoid having domains waiting (for too much time) to run when there are idle pCPUs, even if that is to preserve access locality. |
||
| + | Here it is what the benchmarks tells. In all the graphs [http://xenbits.xen.org/people/dariof/benchmarks/specjbb2005-numa/ here], the light blue line is the interesting one, as it is representative of the case when VM#1 has its affinity set to NODE#0. The most interesting among the various plots is probably this one below: |
||
| − | == Current Status and What’s Coming Next == |
||
| + | http://xenbits.xen.org/people/dariof/benchmarks/specjbb2005-numa/kernbench_avgstd.png |
||
| − | The mentioned patch series is still young, but it’s getting reviewed and a new version is being cooked. At the time of this writing the plan is to keep improving the node affinity aware scheduling, as well as adding VM migration across nodes. That is a very important piece of the whole NUMA support machinery. In fact, it will allow to move all the memory of a VM from a (set of) node(s) to a different one on-line, in case this is needed for any reason (dynamic node load balancing, for instance). The automatic placement heuristics are also being higly restructured, adding more flexibility and putting more factors (e.g., pCPU load) into the play. |
||
| + | We can see the "node affinity" curve managing in getting quite closer to the best case, especially under high system load (4 to 8 VMs). It can't be called as perfect yet, as some more consideration needs to be given to the not-so-loaded cases, but it is a start. If you feel like wanting to help with testing, benchmarking, fixing or whatever... Please, jump in! |
||
| − | Anyway, besides most of the above are developers’ work items for future Xen improvements, we are trying very hard to get at least a snapshot of the automatic NUMA placement in Xen 4.2… Wish us (and yourself!) good luck. |
||
[[Category:Performance]] |
[[Category:Performance]] |
||
Revision as of 11:23, 31 July 2012
Contents
Benchmarking NUMA
Providing a domain with some form of "NUMA Affinity" (see here is very important, especially for performances. That's why both XenD and libxl/xl (starting from Xen 4.2) based toolstacks tries to figure out on their own on what nodes (and as a consequence on what physical CPUs) to put a new domain and pin it there
Dealing with NUMA ny means of cpupools (e.g., xl cpupool-numa-split) is of course possible, but it needs to be setup by hand, while something automatic could be desirable.
The SpecJBB2005 benchmarks has been run concurrently within 1 to 8 (4 VCPUs/1GB RAM) VMs, running on a two NUMA nodes, 16 cores, system with 12 GB of RAM.
NUMA Placement
First of all, just notice that optimally fitting VMs on a NUMA host is an incarnation of the Bin Packing Problem, which means it is NP-hard, so an heuristic approach must be undertaken.
Concentrating on memory, what if we have a bunch of nodes, each with its own amount of free memory, and we need to decide where a new VM should be placed? This RFC patch series includes two patches (8/10 and 9/10) implementing three possible NUMA placement policies:
- greedy, which scans the host’s node and put the VM on the first one that is found to have enough free memory;
- packed, which puts the VM on the node that has the smallest amount of free memory (although still enough for the VM to fit there);
- spread, which puts the VM on the node that has the biggest amount of free memory.
The names comes from the intrinsic characteristics of the three algorithms. In fact, greedy just grabs the first suitable node, packed tends to keep nodes as full as possible while spread tries to keep them as free/empty as possible. Notice that keeping the nodes full or empty should be intended memory-wise here, but that it also imply the following:
- greedy and packed policies are both incline to put as much VMs as possible on one node before moving on to try others (which one does that most, depends on the VMs' characteristics and creation order);
- spread is incline to distribute the VMs across the various nodes (although again, it will depend somehow on VMs' characteristics).
"Scientifically" speaking, greedy is based on the First Fit algorithm, packed is based on Best Fit and spread on Worst Fit.
For benchmarking the placement heuristics (full results available here), on the other hand, all the VMs have been created asking xl to use either the greedy, packed or spread policy. The aggregate throughput is then computed by summing the throughput achieved in all the VMs (and averaging the result).
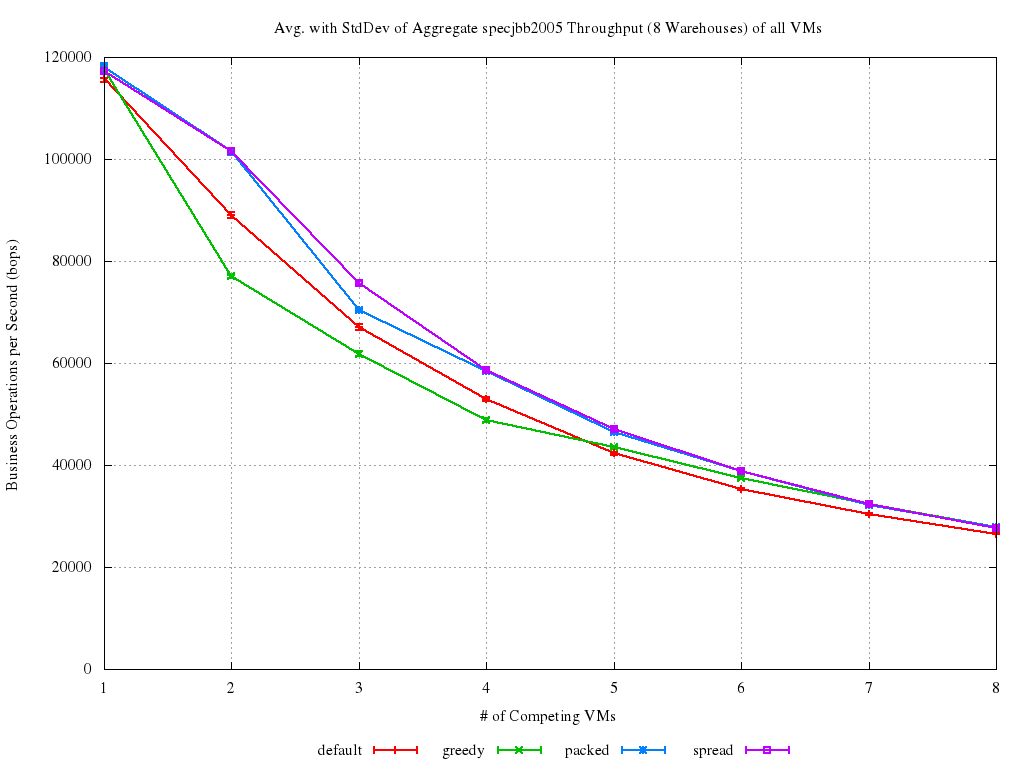
It is easy to see that (in this case) both spread and packed placement works better than unpinned. That should have been expected, especially for spread, as it manages in distributing the load a bit better. Given the specific characteristics of this experiment, it should also have also been expected for greedy to behave very bad when load is small. In fact, with less than 5 VMs, all of them fit on the first NUMA node. This means memory accesses are local, but the load distribution is clearly sub-optimal. Also, the benefit we get from NUMA affinity seems to get smaller with the increase of the VM count. This probably have some relationship with the CPU overcommitment (starting at 5 VM).
NUMA Scheduling
Suppose we have a VM with all its memory allocated on NODE#0 and NODE#2 of our NUMA host. Of course, the best thing to do would be to pin the VM’s vCPUs on the pCPUs related to the two nodes. However, pinning is quite unflexible: what if those pCPUs get very busy while there are completely idle pCPUs on other nodes? It will depend on the workload, but it is not hard to imagine that having some chance to run –even if on a remote node– would be better than not running at all. It would therefore be preferable to give the scheduler some hints about where a VM’s vCPUs should be executed. It then can try at its best to honor these requests of ours, but not at the cost of subverting its own algorithm. From now on, we’ll call this hinting mechanism node affinity (don’t confuse it with CPU affinity, which is about to static CPU pinning).
As said, the experimental patchset introduces also the support for node affinity aware scheduling by means of this changeset: [sched_credit: Let the scheduler know about `node affinity`. As of now, it is all very simple, and it only happens for the credit1 scheduling plugin of the Xen hypervisor. However, looking at some early performance measurements seems promising.
Looking at the results, attempts to suggest the scheduler the preferred node for a VM seem to be the righ direction to go (For the interested, complete results set is here). The various curves in the graph below represents the throughput achieved on one of the VMs, more specifically the one that is being, respectively:
- scheduled without any pinning or affinity, i.e., (cpus="all" in the VM config file, red line, also called default in this article),
- created and pinned on NODE#0, so that all its memory accesses are local (green line),
- scheduled with node affinity only to NODE#0 (no pinning) as per what is introduced by the patch (blue line).
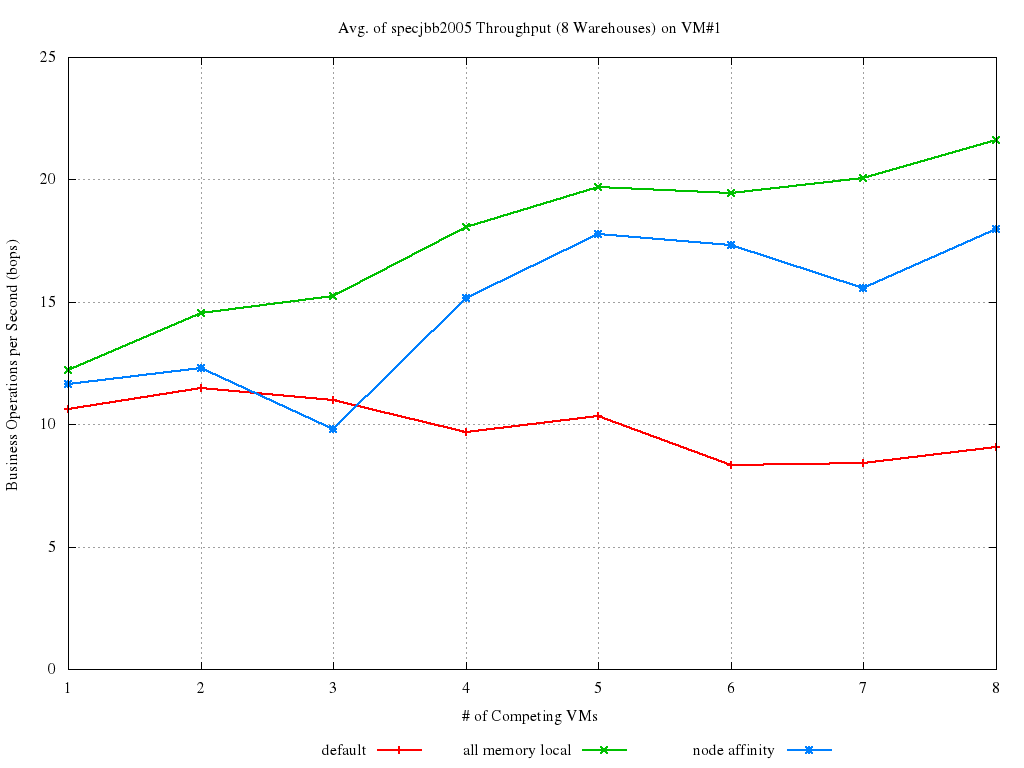
What the plot actually shows is the percent increase of each configuration with respect to the worst possible case (i.e., when all memory access are remote). This means tweaking node affinity increases performance by ~12% to ~18% from the worst case. Also, it lets us gain up to ~8% performance as compared to unpinned behavior, doing particularly well as load increases. However, although it gets quite close to the green line (which is the best case), there is still probably some performance bits to squeeze from it.
Combining Placement and Scheduling
So, if we do both things, i.e.:
- Introduce some form of automatic domain placement logic in the new Xen toolstack (basically, in xl). This means assigning a "node affinity" to a domain at creation time and asking Xen to stick to it.
- Tweak the scheduler to so that it will strongly prefer to run a domain on the node(s) it has affinity with, but not in a strict manner as it is for pinning. For instance, it would be nice to avoid having domains waiting (for too much time) to run when there are idle pCPUs, even if that is to preserve access locality.
Here it is what the benchmarks tells. In all the graphs here, the light blue line is the interesting one, as it is representative of the case when VM#1 has its affinity set to NODE#0. The most interesting among the various plots is probably this one below:

We can see the "node affinity" curve managing in getting quite closer to the best case, especially under high system load (4 to 8 VMs). It can't be called as perfect yet, as some more consideration needs to be given to the not-so-loaded cases, but it is a start. If you feel like wanting to help with testing, benchmarking, fixing or whatever... Please, jump in!